
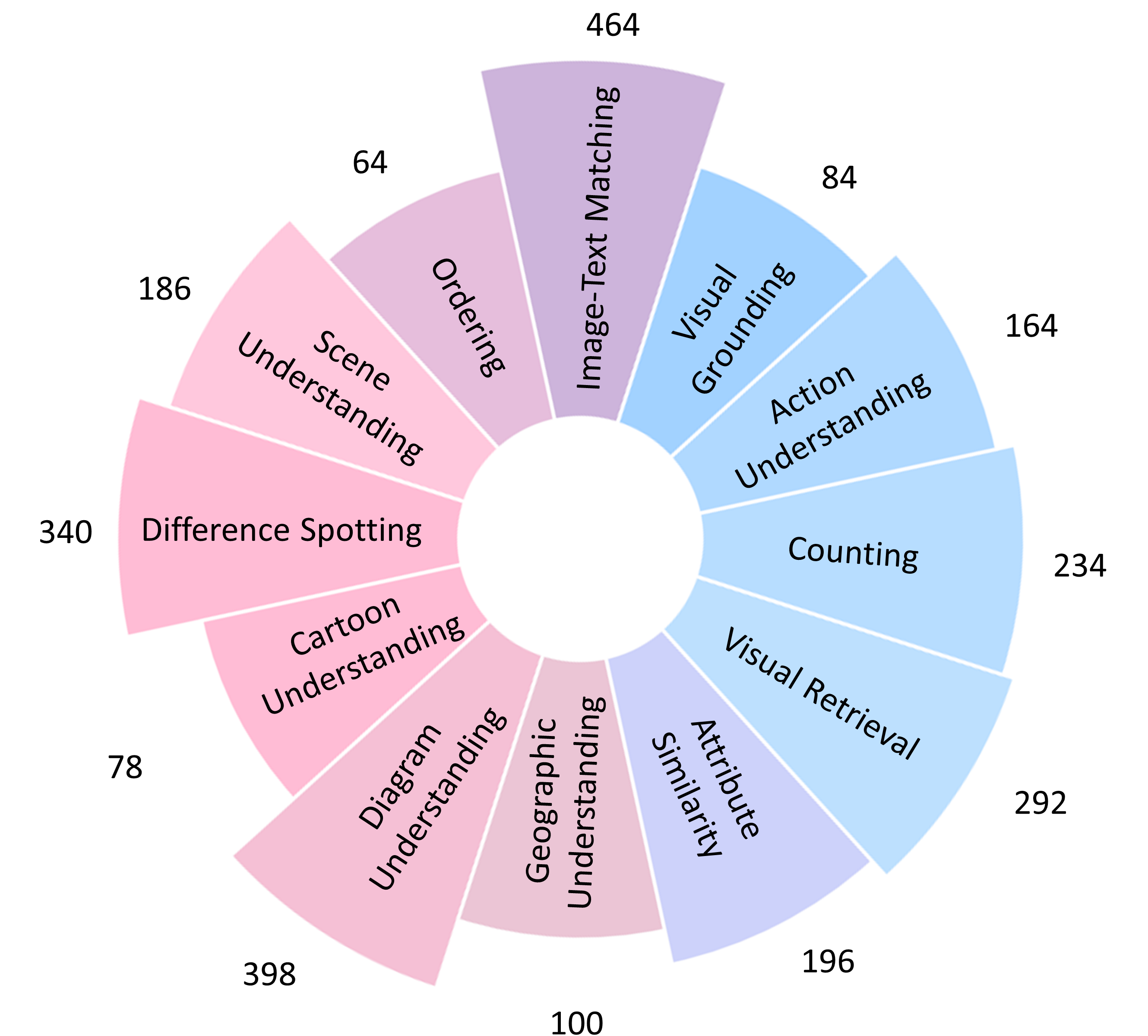
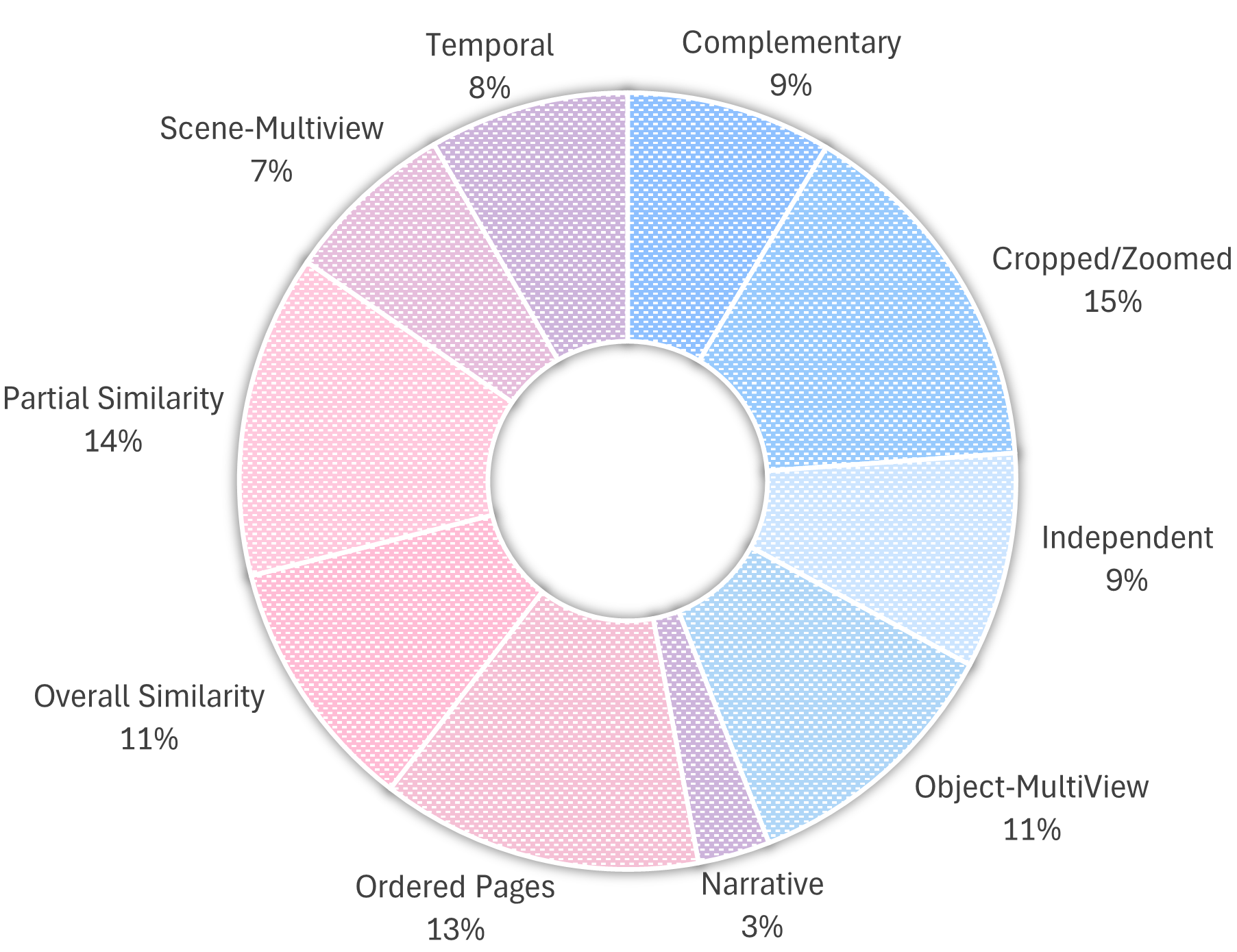
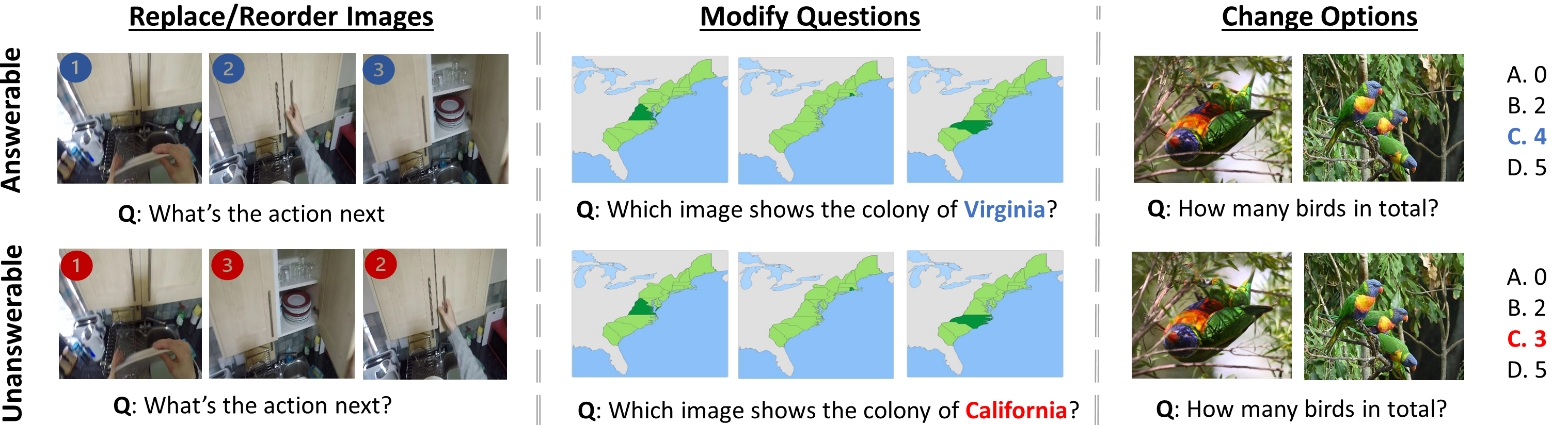
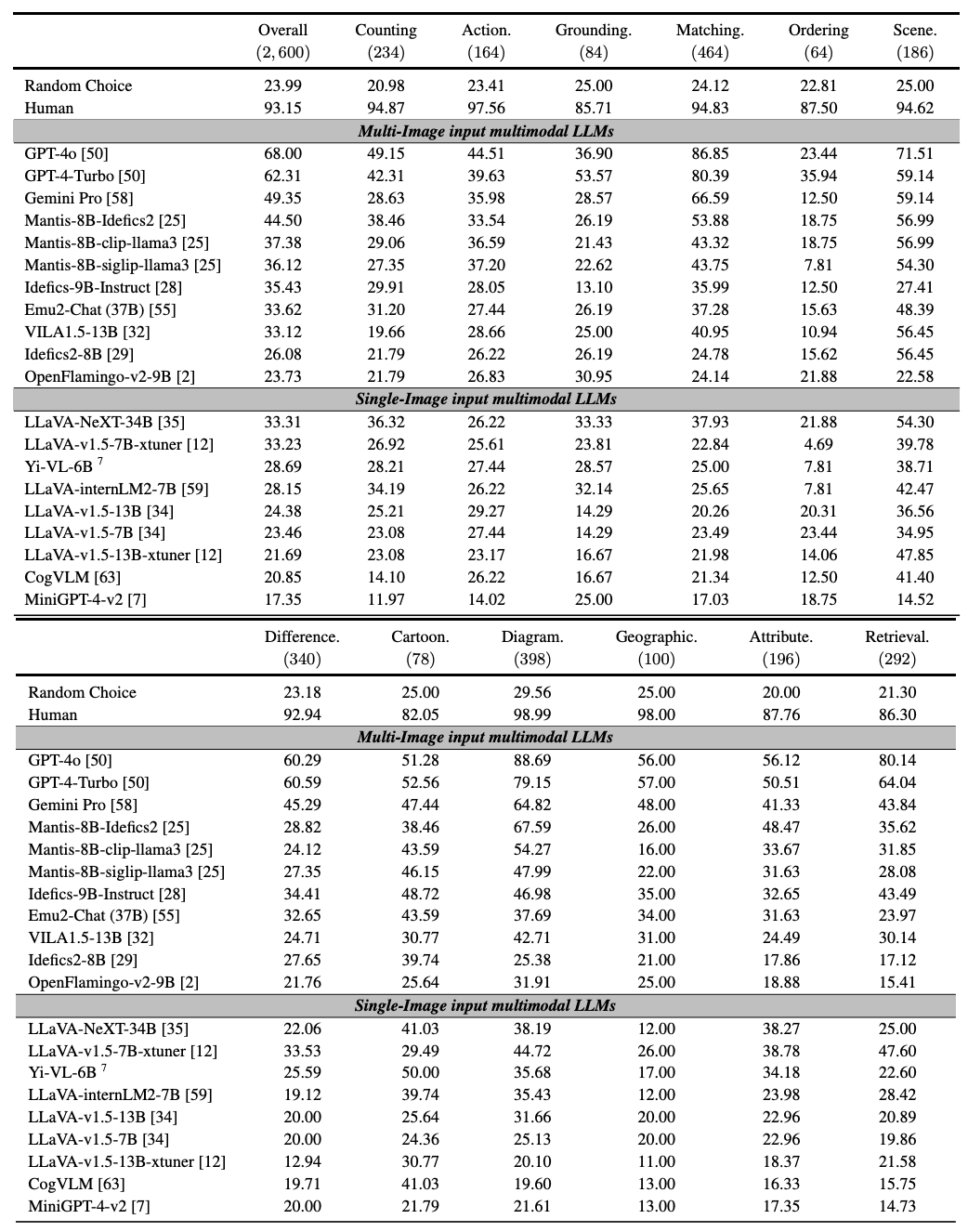
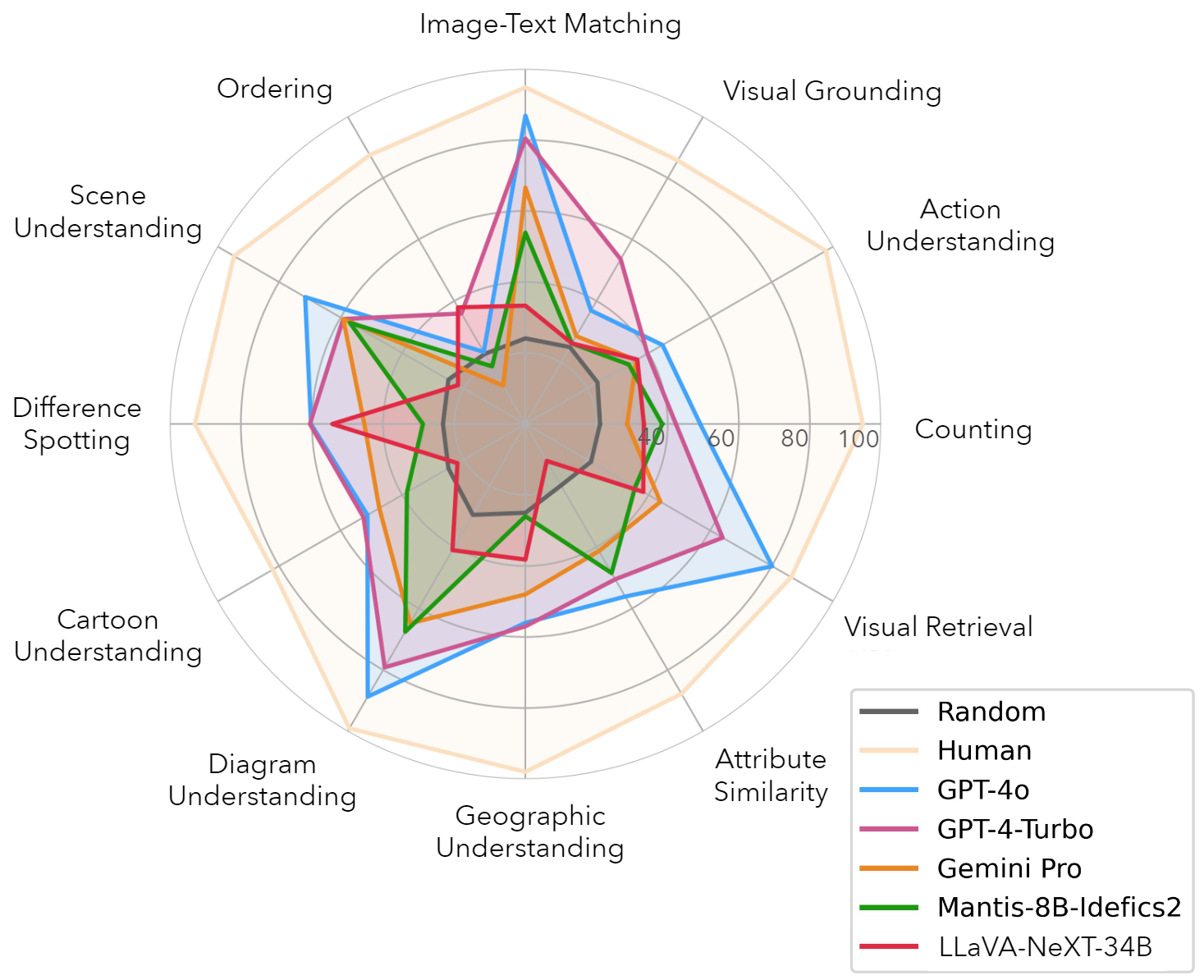
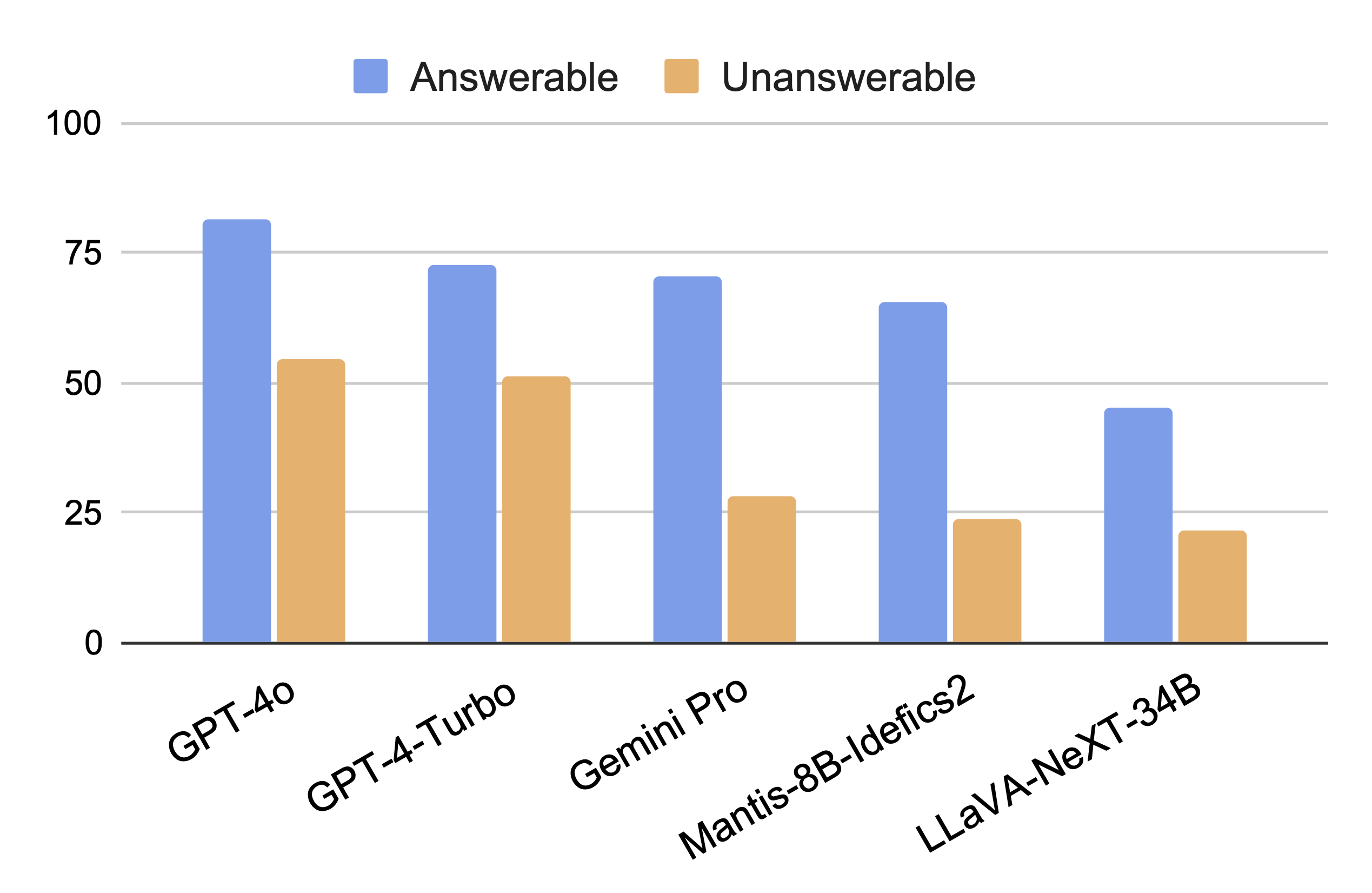
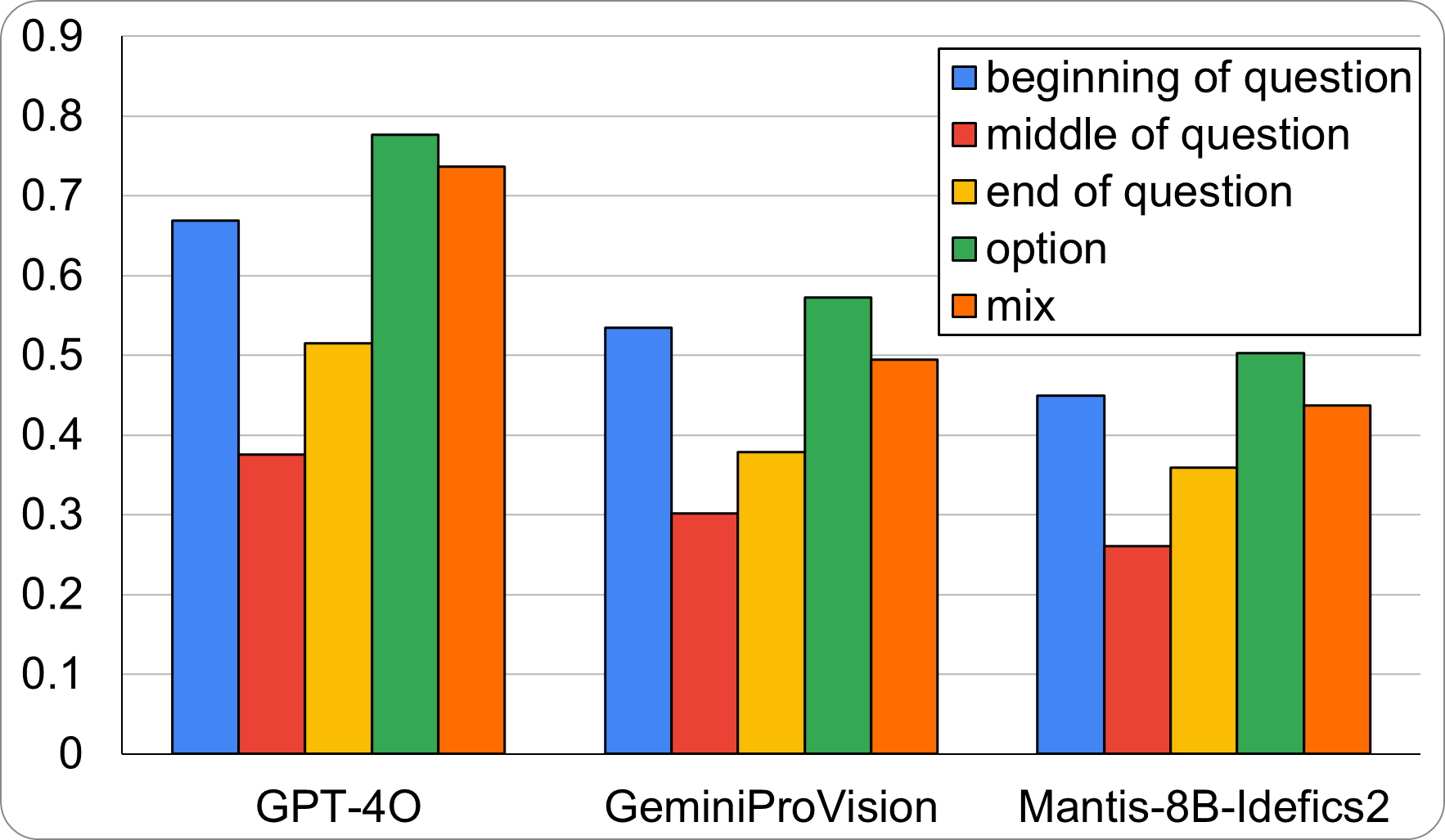
We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). Comprising 11,264 images and 2,600 multiple-choice questions, MuirBench is created in a pairwise manner, where each standard instance is paired with an unanswerable variant that has minimal semantic differences, in order for a reliable assessment. Evaluated upon 20 recent multi-modal LLMs, our results reveal that even the best-performing models like GPT-4o and Gemini Pro find it challenging to solve MuirBench, achieving 68.0% and 49.3% in accuracy. Open-source multimodal LLMs trained on single images can hardly generalize to multi-image questions, hovering below 33.3% in accuracy. These results highlight the importance of MuirBench in encouraging the community to develop multimodal LLMs that can look beyond a single image, suggesting potential pathways for future improvements.
@article{wang2024muirbench,
title={MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding},
author={Wang, Fei and Fu, Xingyu and Huang, James Y and Li, Zekun and Liu, Qin and Liu, Xiaogeng and Ma, Mingyu Derek and Xu, Nan and Zhou, Wenxuan and Zhang, Kai and others},
journal={arXiv preprint arXiv:2406.09411},
year={2024}
}
